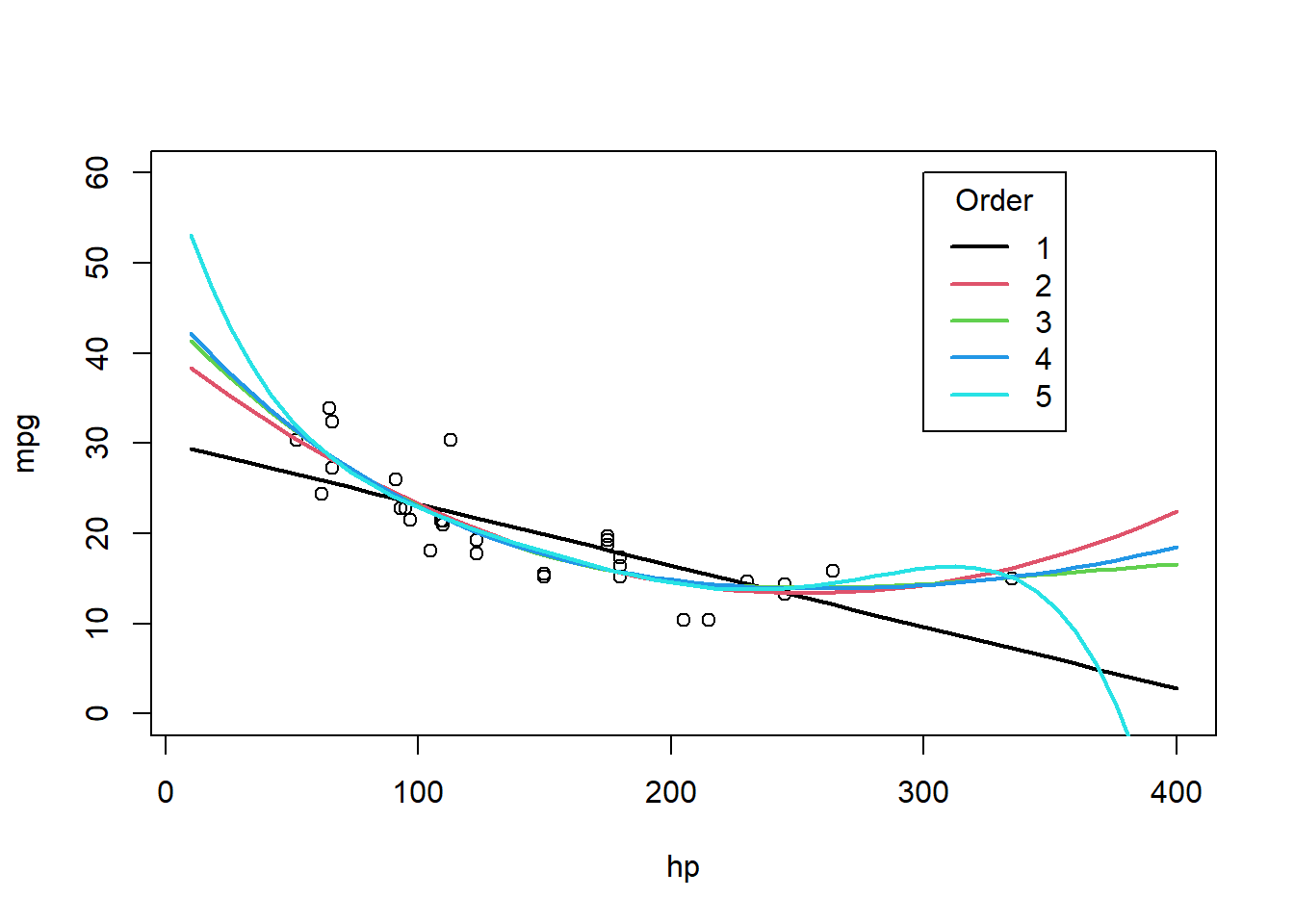
# I'll consider models to predict mpg based on all other predictors. I'll look at AIC for each modelmodel <-lm(mpg ~1+ cyl, data=mtcars)L <-logLik(model, data=mtcars)[1]-2*L +2*(length(coef(model)))
[1] 167.3064
model <-lm(mpg ~1+ cyl+disp, data=mtcars)L <-logLik(model, data=mtcars)[1]-2*L +2*(length(coef(model)))
[1] 165.1456
model <-lm(mpg ~1+ cyl+disp+wt, data=mtcars)L <-logLik(model, data=mtcars)[1]-2*L +2*(length(coef(model)))
[1] 155.5584
model <-lm(mpg ~1+ cyl+disp+wt+qsec, data=mtcars)L <-logLik(model, data=mtcars)[1]-2*L +2*(length(coef(model)))
[1] 155.3037
# Continue until no decrease in AIC is observed
In this code we will compare different multiple regression models to predict miles per gallon from the various predictor variables in the mtcars dataset.
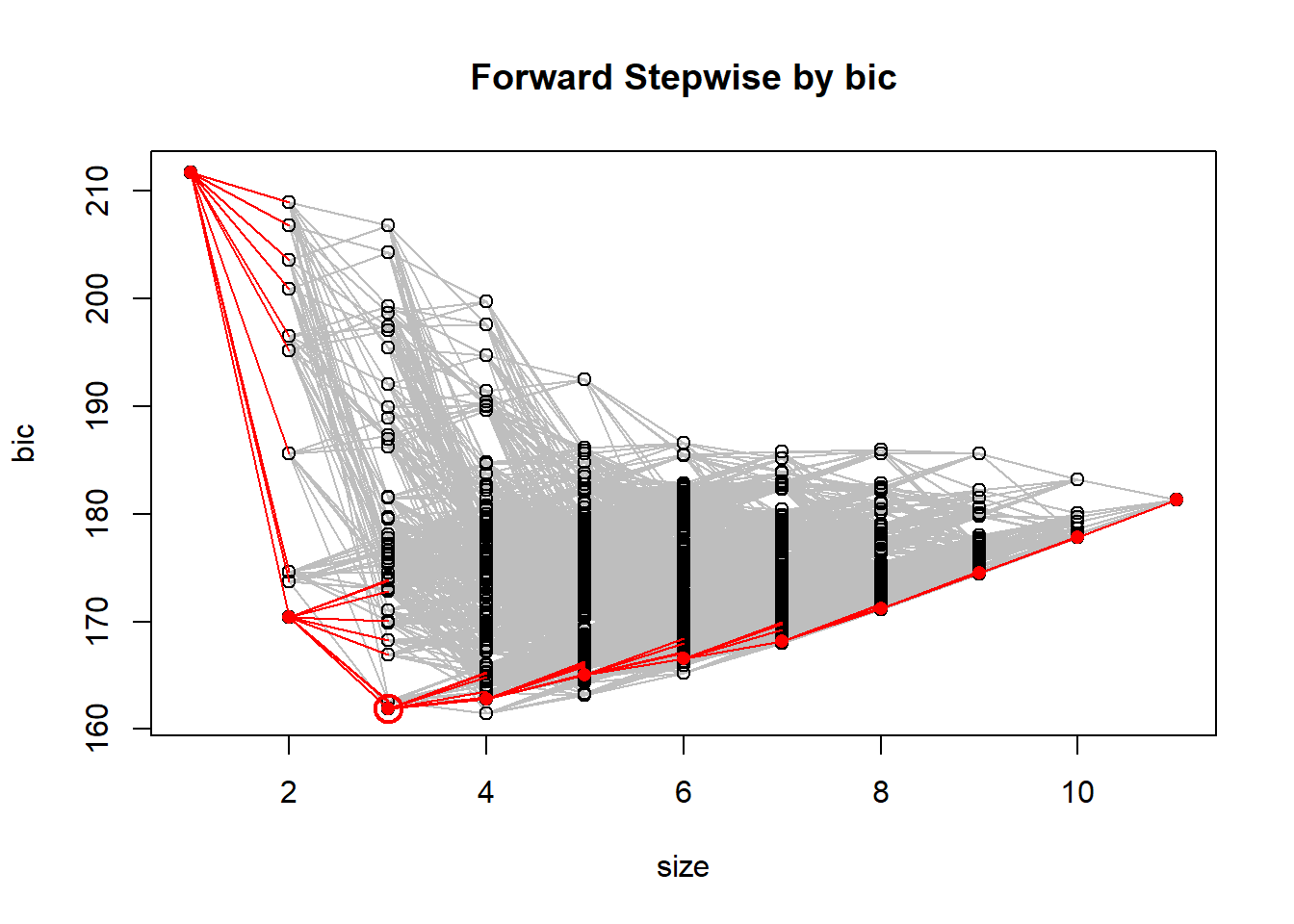
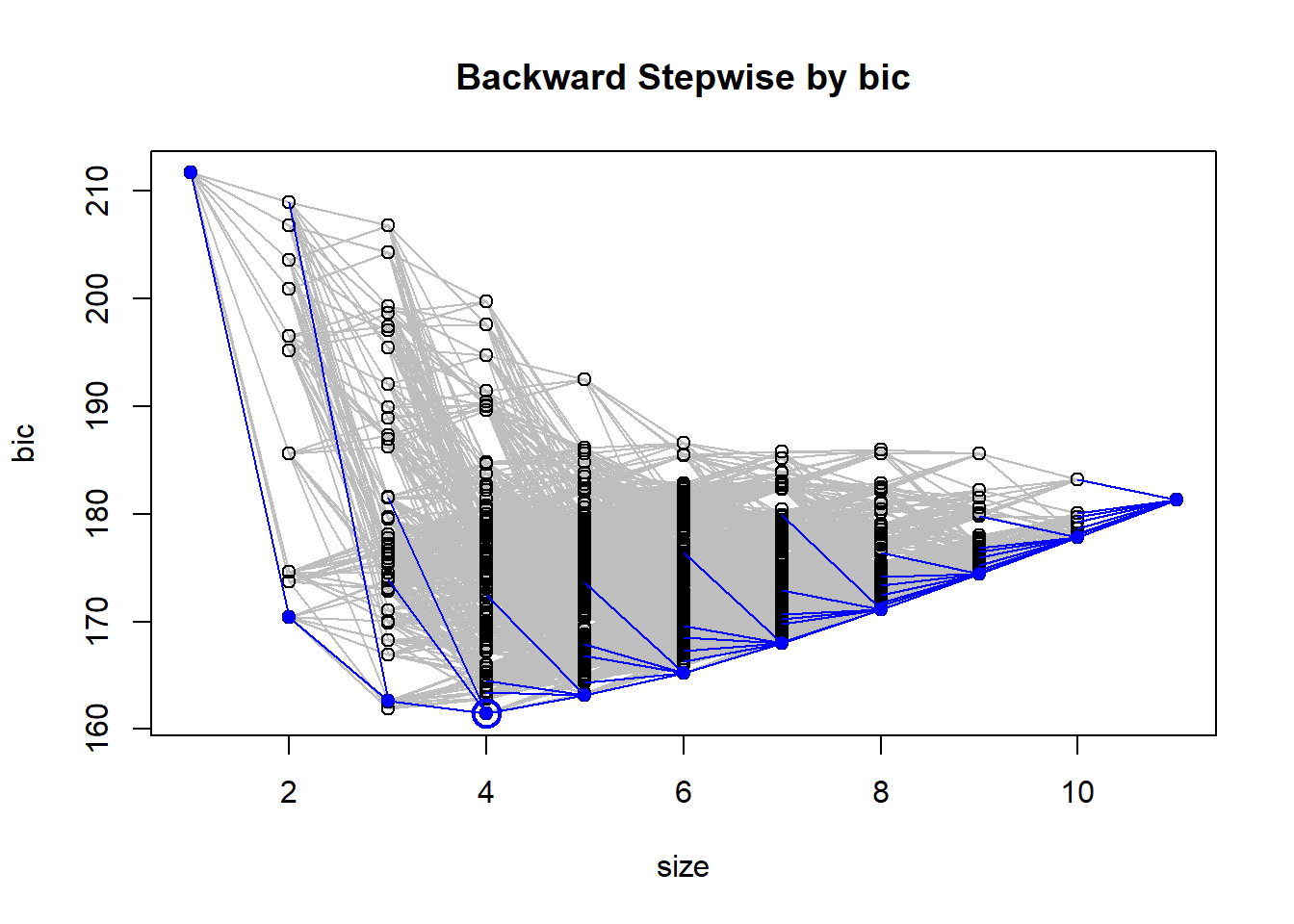
We implement a forward stepwise selection algorithm, and a backwards stepwise selection algorithm. We also have a function that automates K fold validation and gives the formula resulting in the lowest MSE
37.2.2 K fold validation on the models produced
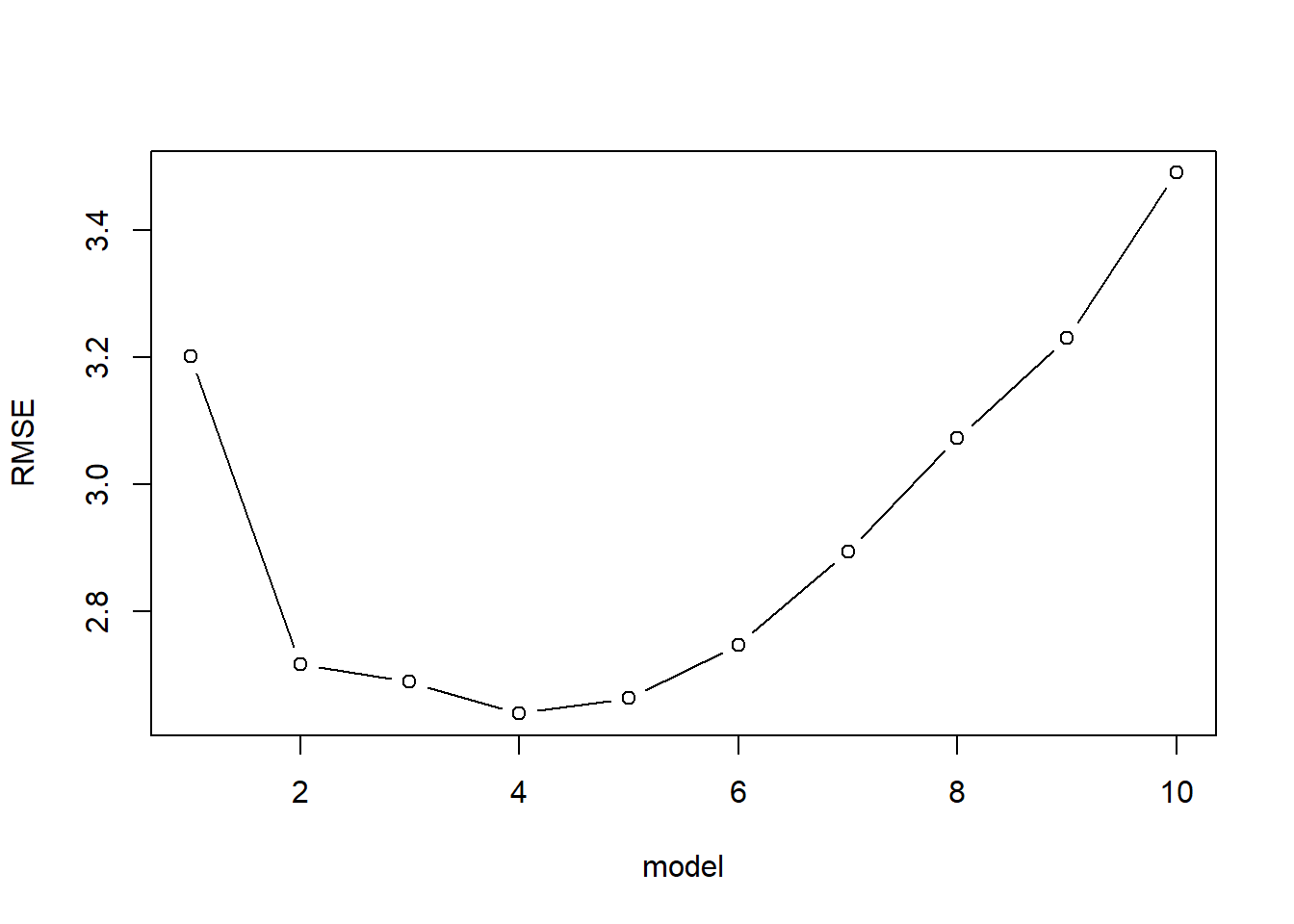
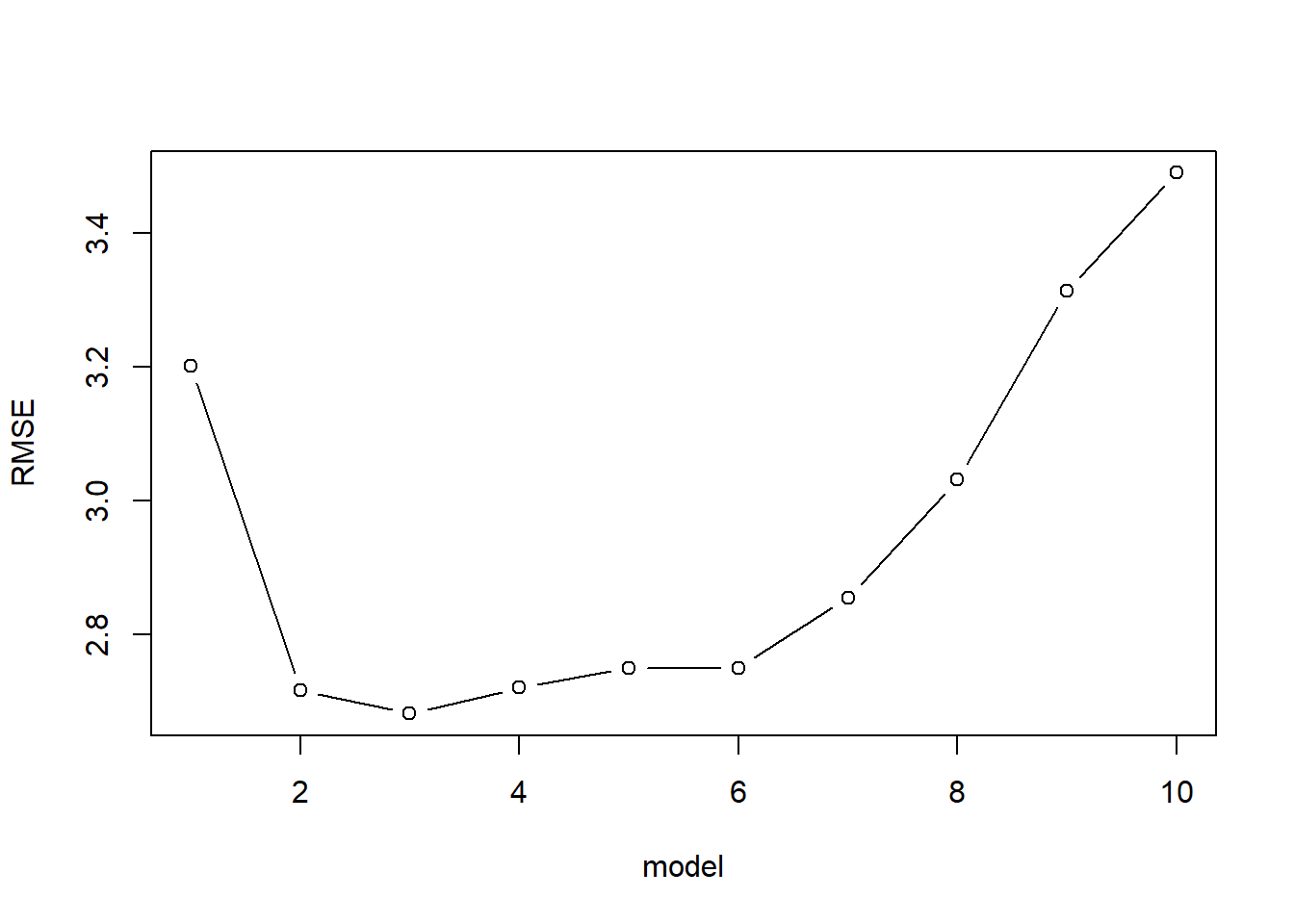
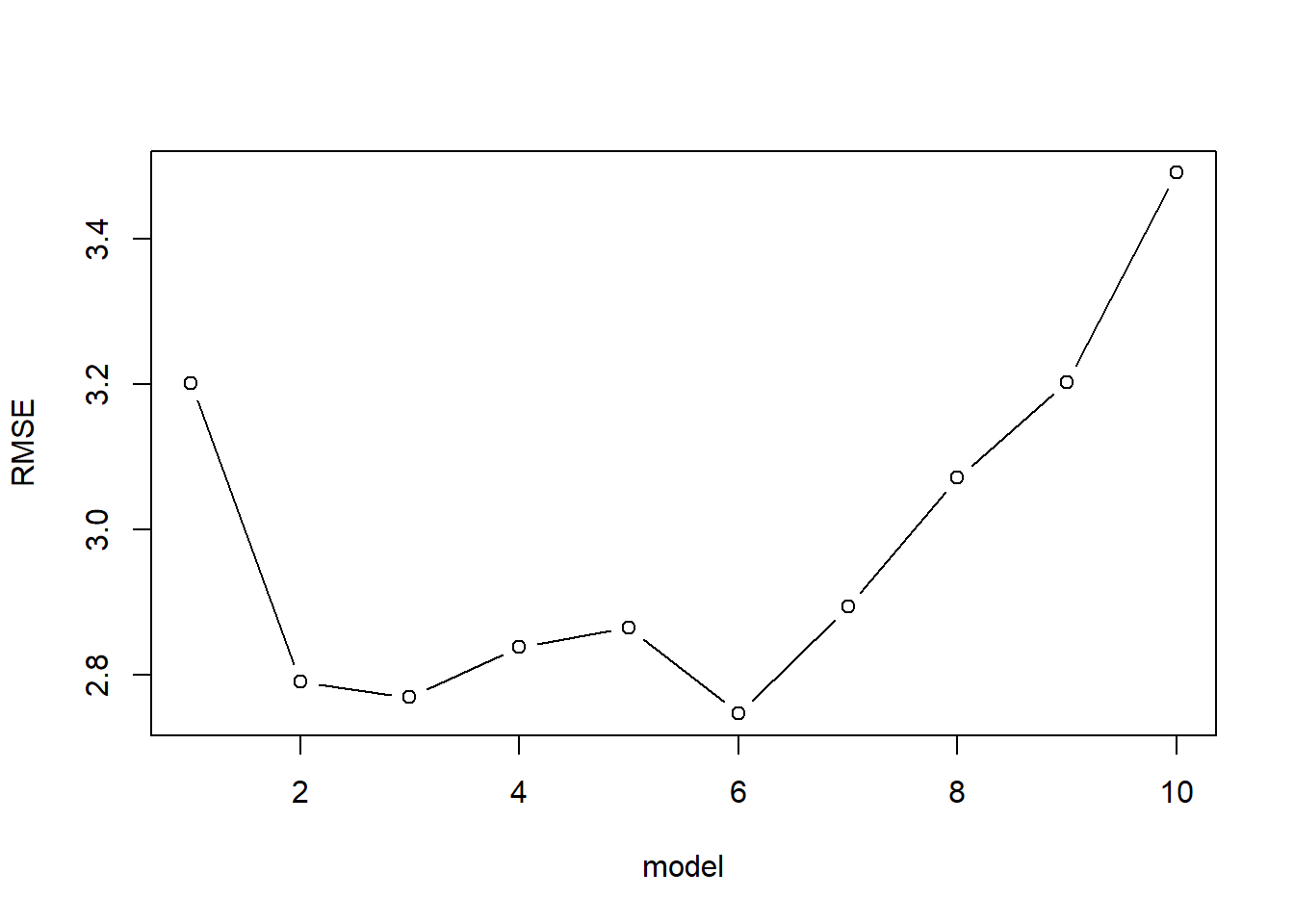
kfoldCV <-function(K, formulas, dataset, responseVar, reps=1){ m <-length(formulas)#an empty data frame to store the results of each validation results <-data.frame(fold =rep(rep(1:K, each=m),times=reps),model =rep(1:m, K*reps),error =0,repl =rep(1:reps, each=m*K)) for(r in1:reps){#idx is a shuffled vector of row numbers idx <-sample(1:nrow(dataset))#folds partitions the row indices folds <-split(idx, as.factor(1:K))for(k in1:K){#split the data into training and testing sets training <- dataset[-folds[[k]],] testing <- dataset[folds[[k]],]#go through each model and estimate MSEfor(f in1:m){#fit the model to the training data fit <-lm(formula = formulas[[f]], data=training)#calculate the average squared error on the testing data results[results$fold == k & results$model == f & results$repl==r, "error"] <-mean((predict(fit, newdata=testing) - testing[,responseVar])^2) } } }#aggregate over each model & replicate, averaging the error aggregated <-aggregate(error~model, data=results, FUN="mean")#produces a simple line & dot plotplot(sqrt(error) ~ model, type="b", data=aggregated, ylab="RMSE")# lines(error ~ model, data=aggregated)print(which(aggregated$error ==min(aggregated$error)))print(formulas[[which(aggregated$error ==min(aggregated$error))]])return(aggregated)}
37.2.3 Model Statistics
A function to take in one or more models and return a data frame giving some comparitive model statistics.
createModelStats <-function(formulas, dataset){ n <-nrow(dataset) model.stats <-data.frame('model'=gsub(" ", "", as.character(formulas), fixed =TRUE))for(m in1:length(formulas)){ modelsum <-summary(lm(formulas[[m]], data=dataset))#I am using k = p+1, the number of predictors + the intercept model.stats$k[m] <-nrow(modelsum$coefficients) model.stats$Rsq[m] <- modelsum$r.squared model.stats$Rsq.adj[m] <- modelsum$adj.r.squared L <-logLik(lm(formulas[[m]], data=mtcars))[1] model.stats$AIC[m] <--2*L +2*model.stats$k[m] model.stats$BIC[m] <--2*L + model.stats$k[m] *log(n) }return(model.stats) }
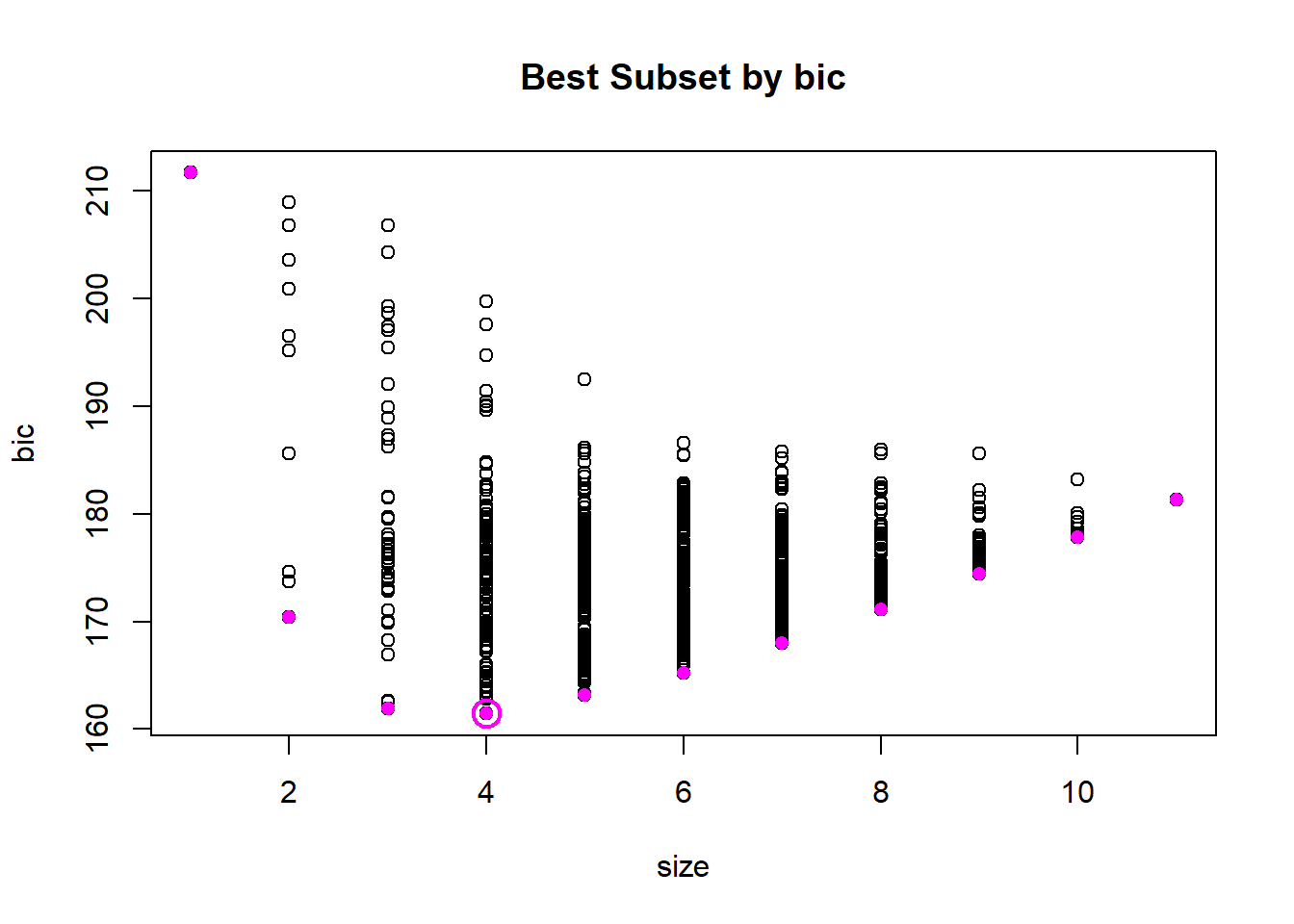
37.2.4 Best Subset Selection
get_model_formula <-function(id, object, outcome){# get models data models <-summary(object)$which[id,-1]# Get model predictors predictors <-names(which(models ==TRUE)) predictors <-paste(predictors, collapse ="+")# Build model formulaas.formula(paste0(outcome, "~", predictors))} bestSubsetSelection <-function(dataset, responseVar, maxModelSize){library(leaps) models <-regsubsets(reformulate(".",responseVar), data = dataset, nvmax = maxModelSize); modelList <-list("formula") nModels <- models$last-models$first+1for(i in1:nModels){ modelList[[i]] <-get_model_formula(i, models, responseVar) }return(modelList) }modelList <-bestSubsetSelection(mtcars, "mpg", 10)kfoldCV(32, modelList, mtcars, "mpg",1)
[1] 4
mpg ~ hp + wt + qsec + am
<environment: 0x000001646666e878>
forwardStepwiseSelection <-function(dataset, responseVar){ predictors =c("1",names(dataset[,-which(names(dataset)==responseVar)])) used =1 M <-list() #empty list to hold all of the models, except M0#the null model and its RSS M0 <-lm(reformulate(predictors[used], responseVar), data=dataset) RSS <-sum(M0$residuals^2)#the list of formulas to return formulas <-list()for(model in1:(length(predictors)-1)){ RSS.best <- RSSfor(try in predictors[-used]){ fitModel <-lm(reformulate(c(predictors[used],try), responseVar), data=dataset) RSS.new <-sum(fitModel$residuals^2)if(RSS.new <= RSS.best){ new.pred <- try RSS.best <- RSS.new } } formulas[[model]] <-reformulate(c(predictors[used],new.pred), responseVar) M[[model]] <-lm(formulas[[model]], data=dataset) RSS <-sum(M[[model]]$residuals^2)print(paste("adding", new.pred, "; RSS = ", RSS)) used <-c(used, which(predictors==new.pred)) }return(formulas) }formulas <-forwardStepwiseSelection(mtcars, "mpg")